I forgot to do some marketing for the following upcoming AI-related courses which will be given in Leuven, Belgium by BNOSAC
- 2019-10-17&18: Statistical Machine Learning with R: Subscribe here
- 2019-11-14&15: Text Mining with R: Subscribe here
- 2019-12-17&18: Applied Spatial Modelling with R: Subscribe here
- 2020-02-19&20: Advanced R programming: Subscribe here
- 2020-03-12&13: Computer Vision with R and Python: Subscribe here
- 2020-03-16&17: Deep Learning/Image recognition: Subscribe here
- 2020-04-22&23: Text Mining with R: Subscribe here
- 2020-05-06&07: Text Mining with Python: Subscribe here
Hope to see you there.
We have been blogging about udpipe several times now in the following posts:
Dependency parsing
A point which we haven't touched upon yet too much was dependency parsing. Dependency parsing is an NLP technique which provides to each word in a sentence the link to another word in the sentence, which is called it's syntactical head. This link between each 2 words furthermore has a certain type of relationship giving you further details about it.
The R package udpipe provides such a dependency parser. With the output of dependency parsing, you can answer questions like
- What is the nominal subject of a text
- What is the object of a verb
- Which word modifies a noun
- What is the linked to negative words
- Which words are compound statements
- What are noun phrases, verb phrases in the text
Examples
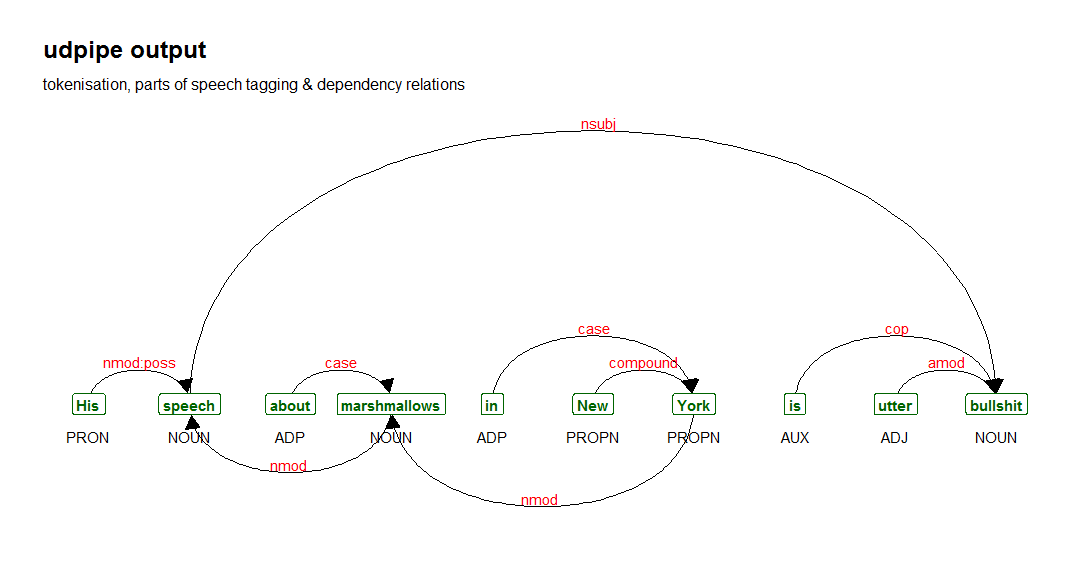
In the following sentence:
His speech about marshmallows in New York is utter bullshit
you can see this dependency parsing in action in the graph below. You can see compound statement like 'New York', that the word speech is linked to the word bullshit with relationship nominal subject, that the 2 nominals marshmallow and speech are linked as nominal noun modifiers, that the word utter is an adjective which modifies the noun bullshit.
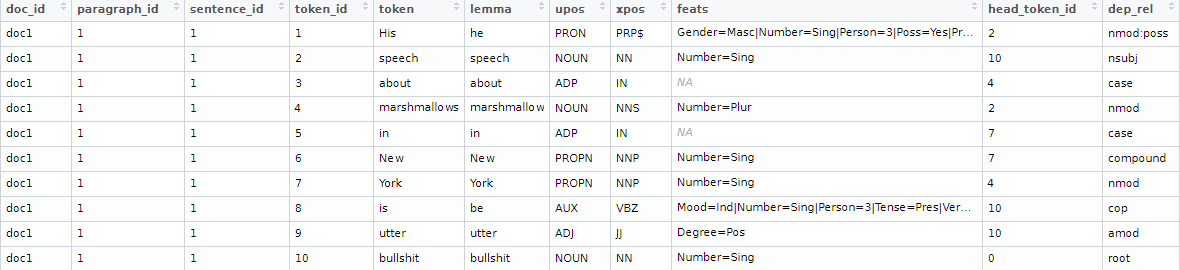
Obtaining such relationships in R is pretty simple nowadays. Running this code, will provide you the dependency relationships among the words of the sentence in the columns token_id, head_token_id and dep_rel. The possible values in the field dep_rel are defined at https://universaldependencies.org/u/dep/index.html.
library(udpipe)
x <- udpipe("His speech about marshmallows in New York is utter bullshit", "english")
R is excellent in visualisation. For visualising the relationships between the words which were found, you can just use the ggraph R package. Below we create a basic function which selects the right columns from the annotation and puts it into a graph.
library(igraph)
library(ggraph)
library(ggplot2)
plot_annotation <- function(x, size = 3){
stopifnot(is.data.frame(x) & all(c("sentence_id", "token_id", "head_token_id", "dep_rel",
"token_id", "token", "lemma", "upos", "xpos", "feats") %in% colnames(x)))
x <- x[!is.na(x$head_token_id), ]
x <- x[x$sentence_id %in% min(x$sentence_id), ]
edges <- x[x$head_token_id != 0, c("token_id", "head_token_id", "dep_rel")]
edges$label <- edges$dep_rel
g <- graph_from_data_frame(edges,
vertices = x[, c("token_id", "token", "lemma", "upos", "xpos", "feats")],
directed = TRUE)
ggraph(g, layout = "linear") +
geom_edge_arc(ggplot2::aes(label = dep_rel, vjust = -0.20),
arrow = grid::arrow(length = unit(4, 'mm'), ends = "last", type = "closed"),
end_cap = ggraph::label_rect("wordswordswords"),
label_colour = "red", check_overlap = TRUE, label_size = size) +
geom_node_label(ggplot2::aes(label = token), col = "darkgreen", size = size, fontface = "bold") +
geom_node_text(ggplot2::aes(label = upos), nudge_y = -0.35, size = size) +
theme_graph(base_family = "Arial Narrow") +
labs(title = "udpipe output", subtitle = "tokenisation, parts of speech tagging & dependency relations")
}
We can now call the function as follows to get the plot shown above:
plot_annotation(x, size = 4)
Let us see what is gives with the following sentence.
The economy is weak but the outlook is bright
x <- udpipe("The economy is weak but the outlook is bright", "english")
plot_annotation(x, size = 4)
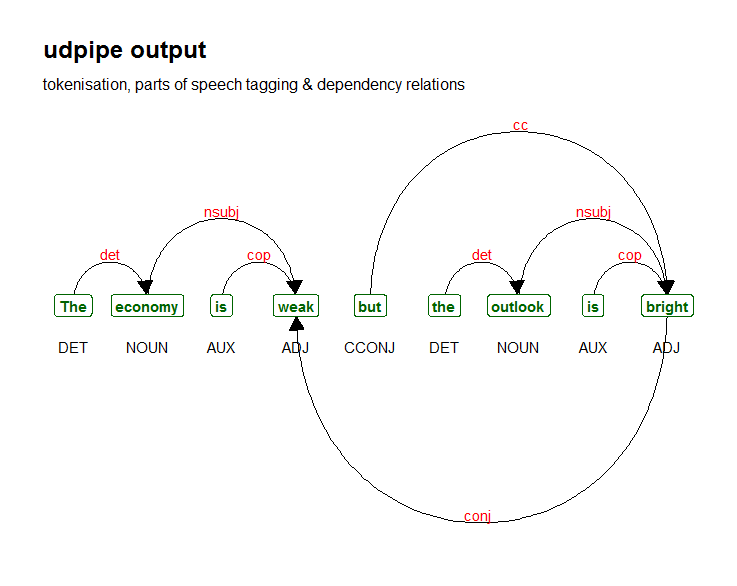
You can see that with dependency parsing you can now answer the question 'What is weak?', it is the economy. 'What is bright?', it is the outlook as these nouns relate to the adjectives with nominal subject as type of relationship. That's a lot more rich information than just looking at wordclouds.
Hope this has triggered beginning users of natural language processing that there is a myriad of NLP options beyond mere frequency based word counting. Enjoy!
I'm happy to announce that the R package udpipe was updated recently on CRAN. CRAN now hosts version 0.8.3 of udpipe. The main features incorporated in the update include
- parallel NLP annotation across your CPU cores
- default models now use models trained on Universal Dependencies 2.4, allowing to do annotation in 64 languages, based on 94 treebanks from Universal Dependencies. We now have models built on afrikaans-afribooms, ancient_greek-perseus, ancient_greek-proiel, arabic-padt, armenian-armtdp, basque-bdt, belarusian-hse, bulgarian-btb, buryat-bdt, catalan-ancora, chinese-gsd, classical_chinese-kyoto, coptic-scriptorium, croatian-set, czech-cac, czech-cltt, czech-fictree, czech-pdt, danish-ddt, dutch-alpino, dutch-lassysmall, english-ewt, english-gum, english-lines, english-partut, estonian-edt, estonian-ewt, finnish-ftb, finnish-tdt, french-gsd, french-partut, french-sequoia, french-spoken, galician-ctg, galician-treegal, german-gsd, gothic-proiel, greek-gdt, hebrew-htb, hindi-hdtb, hungarian-szeged, indonesian-gsd, irish-idt, italian-isdt, italian-partut, italian-postwita, italian-vit, japanese-gsd, kazakh-ktb, korean-gsd, korean-kaist, kurmanji-mg, latin-ittb, latin-perseus, latin-proiel, latvian-lvtb, lithuanian-alksnis, lithuanian-hse, maltese-mudt, marathi-ufal, north_sami-giella, norwegian-bokmaal, norwegian-nynorsk, norwegian-nynorsklia, old_church_slavonic-proiel, old_french-srcmf, old_russian-torot, persian-seraji, polish-lfg, polish-pdb, polish-sz, portuguese-bosque, portuguese-br, portuguese-gsd, romanian-nonstandard, romanian-rrt, russian-gsd, russian-syntagrus, russian-taiga, sanskrit-ufal, serbian-set, slovak-snk, slovenian-ssj, slovenian-sst, spanish-ancora, spanish-gsd, swedish-lines, swedish-talbanken, tamil-ttb, telugu-mtg, turkish-imst, ukrainian-iu, upper_sorbian-ufal, urdu-udtb, uyghur-udt, vietnamese-vtb, wolof-wtb
- some fixes as indicated in the NEWS file
How does parallel NLP annotation looks like right now? Let's do some annotation in French.
library(udpipe)
data("brussels_reviews", package = "udpipe")
x <- subset(brussels_reviews, language %in% "fr")
x <- data.frame(doc_id = x$id, text = x$feedback, stringsAsFactors = FALSE)
anno <- udpipe(x, "french-gsd", parallel.cores = 1, trace = 100)
anno <- udpipe(x, "french-gsd", parallel.cores = 4) ## this will be 4 times as fast if you have 4 CPU cores
View(anno)
Note that udpipe particularly works great in combination with the following R packages
And nothing stops you from using R packages tm / tidytext / quanteda or text2vec alongside it!
Upcoming training schedule
If you want to know more, come attend the course on text mining with R or text mining with Python. Here is a list of scheduled upcoming public courses which BNOSAC is providing each year at the KULeuven in Belgium.
- 2019-10-17&18: Statistical Machine Learning with R: Subscribe here
- 2019-11-14&15: Text Mining with R: Subscribe here
- 2019-12-17&18: Applied Spatial Modelling with R: Subscribe here
- 2020-02-19&20: Advanced R programming: Subscribe here
- 2020-03-12&13: Computer Vision with R and Python: Subscribe here
- 2020-03-16&17: Deep Learning/Image recognition: Subscribe here
- 2020-04-22&23: Text Mining with R: Subscribe here
- 2020-05-05&06: Text Mining with Python: Subscribe here
Last week the R package ruimtehol was updated on CRAN giving R users who perform Natural Language Processing access to the possibility to
- Allow to do semi-supervised learning (learning where you have both text as labels but not always both of them on the same document identifier.
- Allow to do transfer learning by passing on an embedding matrix (e.g. obtained via fasttext or Glove or the like) and keep on training based on that matrix or just use the embeddings in your Natural Language Processing flow.
More information can be found in the package vignette shown below or which you can obtain by installing the package and visiting the vignette with the following R code. Enjoy!
install.packages("ruimtehol")
vignette("ground-control-to-ruimtehol", package = "ruimtehol")