udpipe version 0.7 for Natural Language Processing (#NLP) alongside #tidytext, #quanteda, #tm
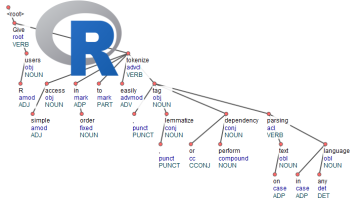 This blogpost announces the release of the udpipe R package version 0.7 on CRAN. udpipe is an R package which does tokenization, parts of speech tagging, lemmatization, morphological feature tagging and dependency parsing. It's main feature is that it is a lightweight R package which works on more than 50 languages and gives you rich NLP output out of the box.
This blogpost announces the release of the udpipe R package version 0.7 on CRAN. udpipe is an R package which does tokenization, parts of speech tagging, lemmatization, morphological feature tagging and dependency parsing. It's main feature is that it is a lightweight R package which works on more than 50 languages and gives you rich NLP output out of the box.
The package was updated mainly in order to more easily work with the crfsuite R package which does entity/intent recogntion and chunking. The user-visible changes that were made are that udpipe now has a shorthand for working with text in the TIF format and it now also allows to indicate the location of the token inside the original text. Next to this, version 0.7 also caches the udpipe models.
Example
Using udpipe (version >= 0.7) works as follows. First download the model of your language and next do the annotation.
library(udpipe)
udmodel <- udpipe_download_model(language = "dutch")
x <- udpipe("De federale regering besliste vandaag dat er een neutrale verpakking voor roltabak en sigaretten komt",
object = udmodel)
Since version 0.7, you can now also directly indicate the language. This will download the udpipe annotation model if it is not already downloaded. Please inspect the help of udpipe_download_model for more details on the languages available and the license of these.
x <- udpipe("Je veux qu’on me juge pour ce que je suis et non pour ce qu’était mon père", "french")
x <- udpipe("Europa lança taxas sobre navios para tirar lixo do fundo do mar.", "portuguese")
x <- udpipe("आपके इस स्नेह्पूर्ण और जोरदार स्वागत से मेरा हृदय आपार हर्ष से भर गया है। मैं आपको दुनिया के सबसे पौराणिक भिक्षुओं की तरफ से धन्यवाद् देता हूँ। मैं आपको सभी धर्मों की जननी कि तरफ से धन्यवाद् देता हूँ, और मैं आपको सभी जाति-संप्रदाय के लाखों-करोड़ों हिन्दुओं की तरफ से धन्यवाद् देता हूँ। मेरा धन्यवाद् उन वक्ताओं को भी जिन्होंने ने इस मंच से यह कहा कि दुनिया में शहनशीलता का विचार सुदूर पूरब के देशों से फैला है।", "hindi")
x <- udpipe("The economy is weak but the outlook is bright", "english")
x <- udpipe("Maxime y su mujer hicieron que nuestra estancia fuera lo mas comoda posible", "spanish")
x <- udpipe("A félmilliárdos MVM-támogatásból 433 milliót négy nyúlfarknyi imázsvideóra költött", "hungarian")
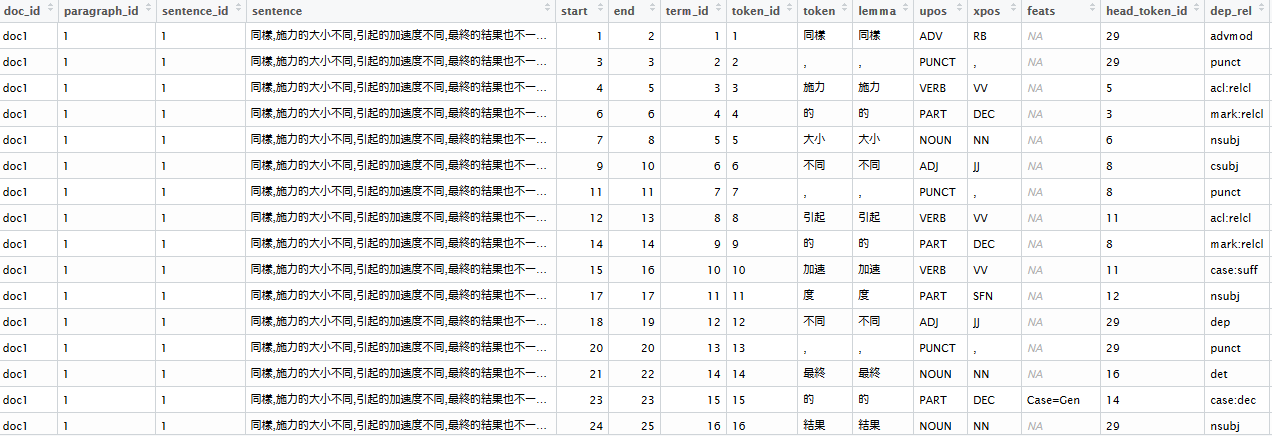
x <- udpipe("同樣,施力的大小不同,引起的加速度不同,最終的結果也不一樣,亦可以從向量的加成性來看", "chinese")
The result is a a data.frame with one row per doc_id and term_id containing all the tokens in the data, the lemma, the part of speech tags, the morphological features, the dependency relationship along the tokens and the location where the token is found in the original text.
Use alongside other R packages
R has a rich NLP ecosystem. If you want to use udpipe alongside other R packages, let's enumerate some basic possibilities where we show how to easily extract lemma's and text of parts of speech tags you are interested in:
Below we show how to use udpipe alongside the 3 popular R packages: tidytext, quanteda and tm on the following data.frame in TIF format.
rawdata <- data.frame(doc_id = c("doc1", "doc2"),
text = c("The economy is weak but the outlook is bright.",
"Natural Language Processing has never been more easy than this."),
stringsAsFactors = FALSE)
Using tidytext
In this code, we let tidytext do tokenisation and use udpipe to enrich the token list. Next we subset the data.frame of tokens by extracting only proper nouns, nouns and adjectives.
library(tidytext)
library(udpipe)
library(dplyr)
x <- unnest_tokens(rawdata, input = text, output = word)
x <- udpipe(split(x$word, x$doc_id), "english")
x <- filter(x, upos %in% c("PROPN", "NOUN", "ADJ"))
Using quanteda
In the code below, we let udpipe do tokenisation and provide the lemma's back in quanteda's tokens element.
library(quanteda)
library(udpipe)
x <- corpus(rawdata, textField = "text")
tokens <- udpipe(texts(x), "english")
x$tokens <- as.tokenizedTexts(split(tokens$lemma, tokens$doc_id))
Using tm
Below, we get only the lemma's of the nouns, proper nouns and adjectives and apply this using the tm_map functionality from tm.
library(tm)
library(udpipe)
x <- VCorpus(VectorSource(rawdata$text))
x <- tm_map(x, FUN=function(txt){
data <- udpipe(content(txt), "english")
data <- subset(data, upos %in% c("PROPN", "NOUN", "ADJ"))
paste(data$lemma, collapse = " ")
})
UDPipe currently already uses deep learning techniques (e.g a GRU network) for doing the tokenisation but the dependency parsing was enhanced in 2018 by incorporating tensorflow. On the roadmap for a next release will be the integration of the UDPipe future enhancements (which got 3rd place at the CoNLL shared task from 2018) including these tensorflow components.
Training on Text Mining
Are you interested in how text mining techniques work, then you might be interested in the following data science courses that are held in the coming months.
- 08-09/10/2018: Text mining with R. Brussels (Belgium). http://di-academy.com/bootcamp + send mail to This email address is being protected from spambots. You need JavaScript enabled to view it.
- 15-16/10/2018: Statistical machine learning with R. Leuven (Belgium). Subscribe here
- 20-21/11/2018: Text mining with R. Leuven (Belgium). Subscribe here
- 19-20/12/2018: Applied spatial modelling with R. Leuven (Belgium). Subscribe here
- 21-22/02/2018: Advanced R programming. Leuven (Belgium). Subscribe here
- 13-14/03/2018: Computer Vision with R and Python. Leuven (Belgium). Subscribe here
- 15/03/2019: Image Recognition with R and Python: Subscribe here
- 01-02/04/2019: Text Mining with R. Leuven (Belgium). Subscribe here