CRAN search based on natural language processing
CRAN contains up to date (October 2017) more than 11500 R packages. If you want to scroll through all of these, you probably need to spend a few days, assuming you need 5 seconds per package and there are 8 hours in a day.
Since R version 3.4, we can also get a dataset will all packages, their dependencies, the package title, the description and even the installation errors which the packages have. Which makes the CRAN database with all packages an excellent dataset for doing text mining. If you want to get that dataset, just do as follows in R:
library(tools)
crandb <- CRAN_package_db()
Based on that data the following CRAN NLP searcher app was built as shown below. I'ts available for inspection at http://datatailor.be:9999/app/cran_search and is a tiny wrapper around the result of annotating the package title and package description using the udpipe R package: https://github.com/bnosac/udpipe
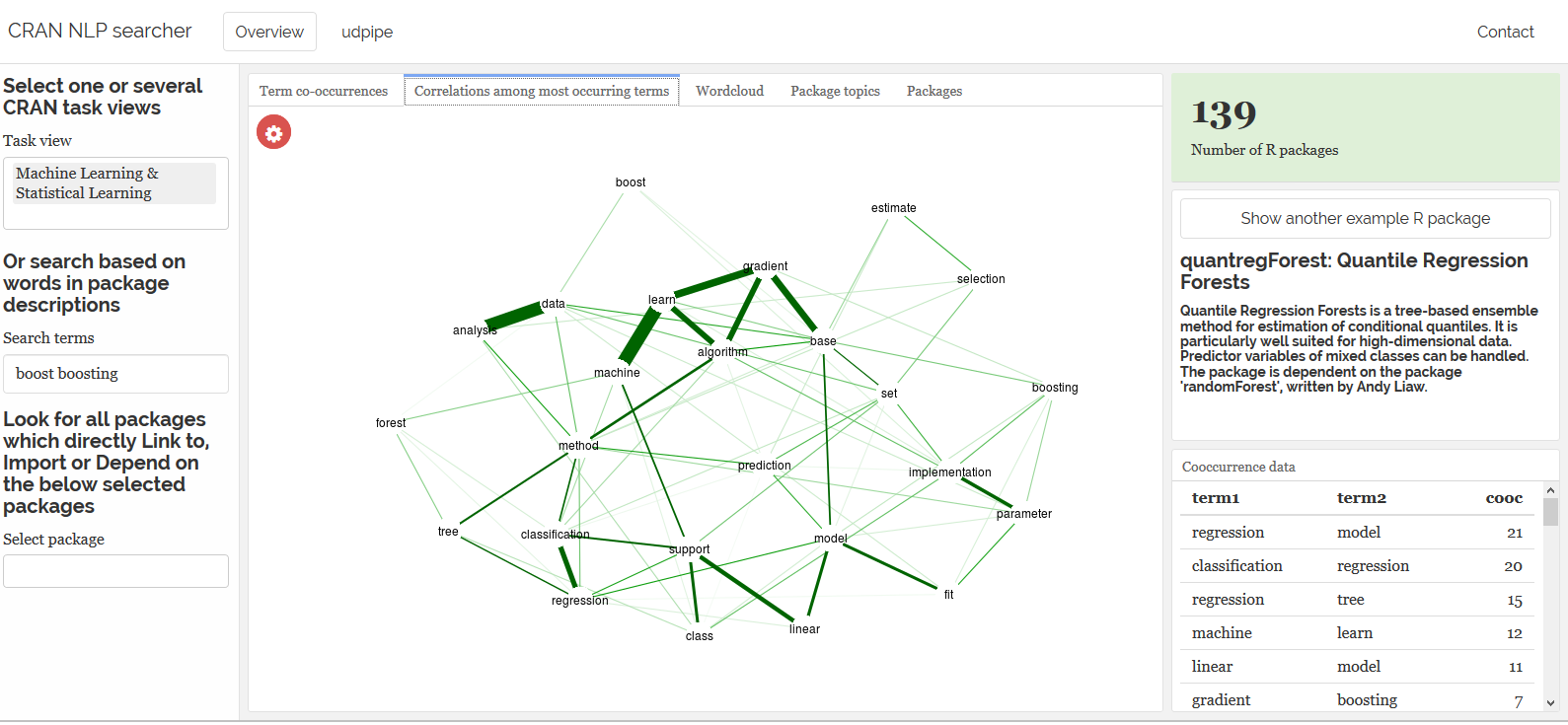
If you want to easily extract what is written in text without reading it, a common way is to do Parts of Speech tagging, extract the nouns and/or the verbs and then plot all co-occurrences / correlations and frequencies of the lemmata. The updipe package allows you exactly to do that. Annotating using Parts of Speech tagging, is pretty easy with udpipe_annotate function from the the udpipe R package (https://github.com/bnosac/udpipe). Mark that this takes a while (as in +/- 30 minutes) and is probably something you want to run as a web-service or integrated stored procedure.
library(udpipe)
ud_model <- udpipe_download_model(language = "english")
ud_model <- udpipe_load_model(ud_model$file_model)
crandb_annotated <- udpipe_annotate(ud_model,
x = paste(crandb$Title, crandb$Description, sep = " \n "),
doc_id = crandb$Package)
crandb_annotated <- as.data.frame(crandb_annotated)
Once we have that data annotated, making a web application which allows you to visualise, structure and display the CRAN packages content is pretty easy with tools like flexdashboard. That's exactly what this web application available at http://datatailor.be:9999/app/cran_search does. The application allows you
- List all packages which are part of a CRAN Task View
- To search for CRAN packages based on what the author has written in the package title and description
- Based on the found CRAN packages which were searched for: Visualise the nouns and verbs in the package title and descriptions by using
- Word-coocurrence graphs indicating how many times each lemma occurs in the same package as another lemma
- Word-correlation graphs showing the positive correlations between the top n most occurring lemma's in the packages
- Word clouds indicating the frequency of nouns/verbs or consecutive nouns/verbs (bigrams) in the package descriptions
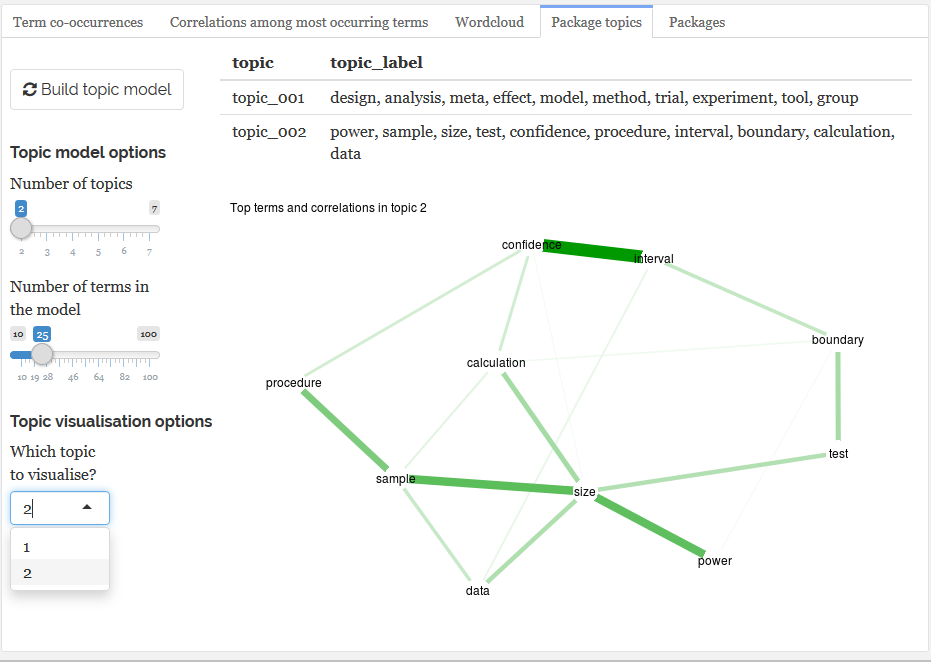
- Build a topic model (latent dirichlet allocation) to cluster packages and visualise them
The web application (flexdashboard) was launched on a small shinyproxy server and is available here: http://datatailor.be:9999/app/cran_search. Can you find topics which are not yet covered by the CRAN task views yet? Can you find the content of the Rcpp-universe or the sp package universe?
If you are interested in these techniques, you can always subscribe for our text mining with R course at the following dates:
- 08+10/11/2017: Text mining with R. Leuven (Belgium). Subscribe here
- 27-28/11/2017: Text mining with R. Brussels (Belgium). http://di-academy.com/bootcamp + send mail to This email address is being protected from spambots. You need JavaScript enabled to view it.
- 19-20/12/2017: Applied spatial modelling with R. Leuven (Belgium). Subscribe here
- 20-21/02/2018: Advanced R programming. Leuven (Belgium). Subscribe here
- 08-09/03/2018: Computer Vision with R and Python. Leuven (Belgium). Subscribe here
- 22-23/03/2018: Text Mining with R. Leuven (Belgium). Subscribe here