An overview of text mining visualisations possibilities with R on the CETA trade agreement
Text Mining has become quite mainstream nowadays as the tools to make a reasonable text analysis are ready to be exploited and give astoundingly nice and reasonable results. At BNOSAC, we use it mainly for text mining on call center data, poetry, salesforce data, emails, HR reviews, IT logged tickets, customer reviews, survey feedback and many more. We also provide training on text mining with R in Belgium (next trainings are scheduled on November 14/15 2016 and March 23/24 2017 in Belgium, to subscribe: go here or here).
For this blog post, we will focus on the most relevant visualisations which exist in text mining by using the CETA trade agreement between the EU and Canada.

This trade agreement is available as a pdf on www.trade.ec.europa.eu/doclib/docs/2014/september/tradoc_152806.pdf and we would like to see what is written in there without having to read all of the 1598 pages in which our politicians in Belgium seem to have found good reasons to at least for a while politically block the process of signing this treaty.
Let us start by reading in the pdf file in R which is pretty easy nowadays.
library(pdftools)
library(data.table)
txt <- pdf_text("tradoc_152806.pdf")
txt <- unlist(txt)
txt <- paste(txt, collapse = " ")
Research done in 2012 (Wikipedia) showed that the average reading speed is 184 words per minute or 863 characters per minute. The CETA treaty has 3091384 characters and 334723 terms (words excluding punctuations). A quick calculation tells me that reading this document would take me between 30 and 59 hours non-stop. Were are not going to do this but instead do some text mining on the CETA treaty.
If you are doing text mining, people refer to text as part of documents. In this case there is only 1 document, the CETA treaty. For further analysis, we will assume that each article of the CETA treaty is a document. As you can see in the following screenshot, the article starts always with the word article and next some numbers. Let's extract this so that we have a dataset with 453 articles, the header and the content. The R code for this is put at https://github.com/jwijffels/ceta-txtmining/blob/master/01_import_ceta_treaty_pos_tagging.R. This dataset is available at https://github.com/jwijffels/ceta-txtmining.

A first step in text mining is always to do a Parts-of-Speech (POS) tagging. This assigns to each word a tag (noun, verb, adverb, adjective, pronoun, ...). Mostly you are only interested in nouns and some verbs and POS tagging allows you to easily do this. POS tagging for Dutch/French/English/German/Spanish/Italian can be done with the pattern.nlp package available at https://github.com/bnosac/pattern.nlp. We do this for all 453 articles in the treaty and show the distribution of the POS tags.
## Natural Language Processing: POS tagging
library(pattern.nlp)
ceta_tagged <- mapply(article.id = ceta$article.id, content = ceta$txt, FUN=function(article.id, content){
out <- pattern_pos(x = content, language = "english", core = TRUE)
out$article.id <- rep(article.id, times = nrow(out))
out
}, SIMPLIFY = FALSE)
ceta_tagged <- rbindlist(ceta_tagged)
## Take only nouns
ceta_nouns <- subset(ceta_tagged, word.type %in% c("NN") & nchar(word.lemma) > 2)
## All data in 1 list
ceta <- list(ceta_txt = txt, ceta = ceta, ceta_tagged = ceta_tagged, ceta_nouns = ceta_nouns)
## Look at POS tags
library(lattice)
barchart(sort(table(ceta$ceta_tagged$word.type)), col = "lightblue", xlab = "Term frequency",
main = "Parts of Speech Tag term frequency\n in CETA treaty")
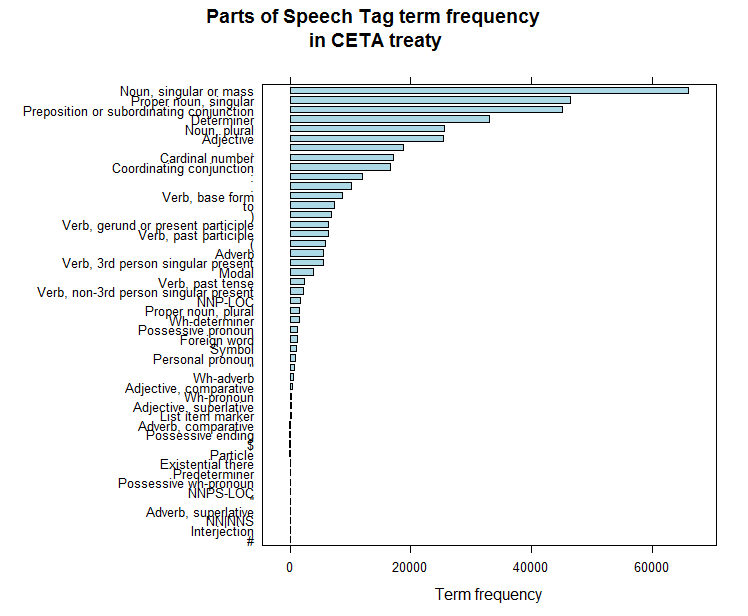
In what comes further, we only work on the nouns (POS tags NN). The data preparation for the text analysis is now done, we have a dataset with 1 row per word and the corresponding tag. We can now start to do some analysis and to make some graphs
In order to split up the 453 articles into relevant topics, we generate a topic model (code can be found here). Let's hope we find an indication that some part of the treaty will indeed cover the issues the Walloon minister president Paul Magnette was talking about. The core R code which fits this is shown below and fits a topic model with 5 topics on the top 250 terms occurring in the CETA treaty.
ceta_topics <- LDA(x = dtm[, topterms], k = 5, method = "VEM", control = list(alpha = 0.1, estimate.alpha = TRUE, seed = as.integer(10:1), verbose = FALSE, nstart = 10, save = 0, best = TRUE))
Can we find the topic which Mr Magnette was talking about? Yes it is topic 3 which emits the words claim, dispute, investment certainty, enterprise, decision and authority, these words will be visualised later on. If we were only interested in this, we can use the topic model to score the treaty and limit the further reading of that document to the 196 articles which cover that. Instead, we will show which typical text mining graphs can be generated with R.
1. Text Mining is mostly about frequency statistics of terms
Wordclouds are a commonly used way to display how many times each word is occurring in the text. You can easily do this with the wordcloud or wordcloud2 R package. The following code calculates how many times each noun is occurring and plots these in a wordcloud. The wordcloud2 package gives HTML as output and allows also to set a background image like an image of the Canada flag and the EU.
## Word frequencies
x <- ceta$ceta_nouns[, list(n = .N), by = list(word.lemma)]
x <- x[order(x$n, decreasing = TRUE), ]
x <- as.data.frame(x)
## Visualise them with wordclouds
library(wordcloud)
wordcloud(words = x$word.lemma, freq = x$n, max.words = 150, random.order = FALSE, colors = brewer.pal(8, "Dark2"))
library(wordcloud2)
wordcloud2(data = head(x, 700), figPath = "maple_europa_black.png")
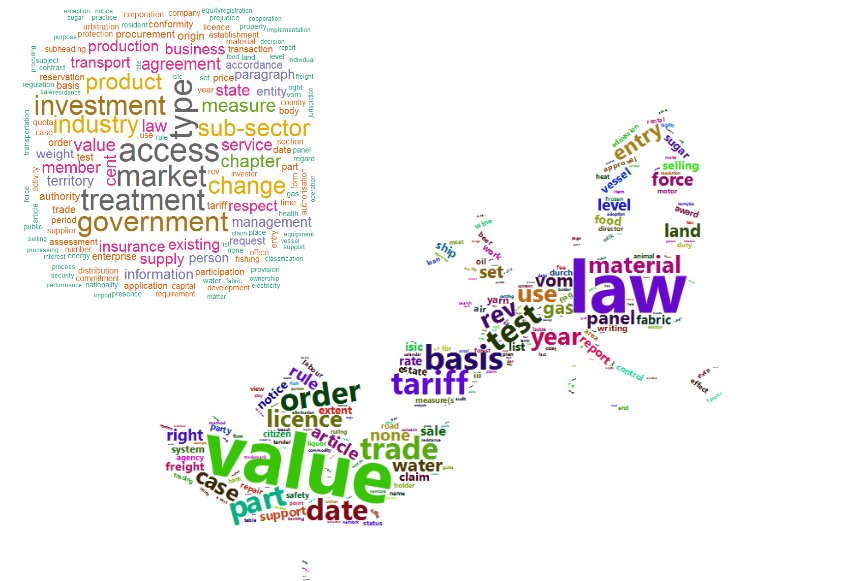
2. But text mining is also about co-occurrence statistics
Co-occurrence statistics indicate how many times 2 words are occuring in the same CETA article. That is great as it gives more indication of how word are used in its context. For this, you can rely on the ggraph & ggforce R packages. The following shows the top 70 word pairs which co-occur and visualises them.
library(ggraph)
library(ggforce)
library(igraph)
library(tidytext)
word_cooccurences <- pair_count(data=ceta$ceta_nouns, group="article.id", value="word.lemma", sort = TRUE)
set.seed(123456789)
head(word_cooccurences, 70) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n)) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1.8, col = "darkgreen") +
ggtitle(sprintf("\n%s", "CETA treaty\nCo-occurrence of nouns")) +
theme_void()
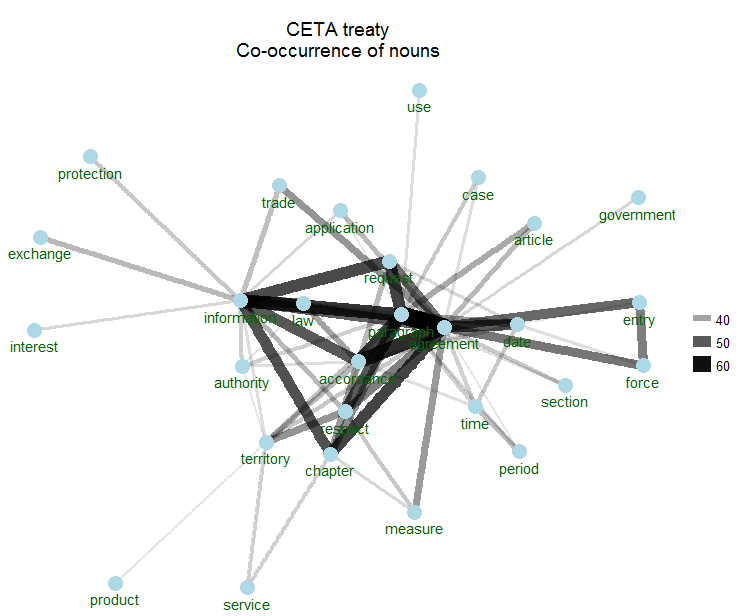
3. And text mining is also about correlations between words
Text mining is also about visualising which words are used next to other words. One can use correlations for that which can be visualised. The following graph shows the top 25 correlations of the words emmitted by topic 3 (the Mr Magnette topic which generated some media fuzz). It shows the words emitted by topic 3, these are words like: claim, dispute, investment certainty, enterprise, decision and authorit ). This correlation visualisation clearly shows the correlations between the words which got into the news recently namely investor claims of enterprises, investment certainties, who is deciding on that and when does this new type of procedure get into place.
library(topicmodels.utils)
idx <- predict(ceta_topics, dtm, type = "topics")
idx <- idx$topic == 3
termcor <- termcorrplot(dtm[idx, ],
words = names(ceta_topic_terms$topic3), highlight = head(names(ceta_topic_terms$topic3), 3),
autocorMax = 25, lwdmultiplier = 3, drawlabel = TRUE, cex.label = 0.8)
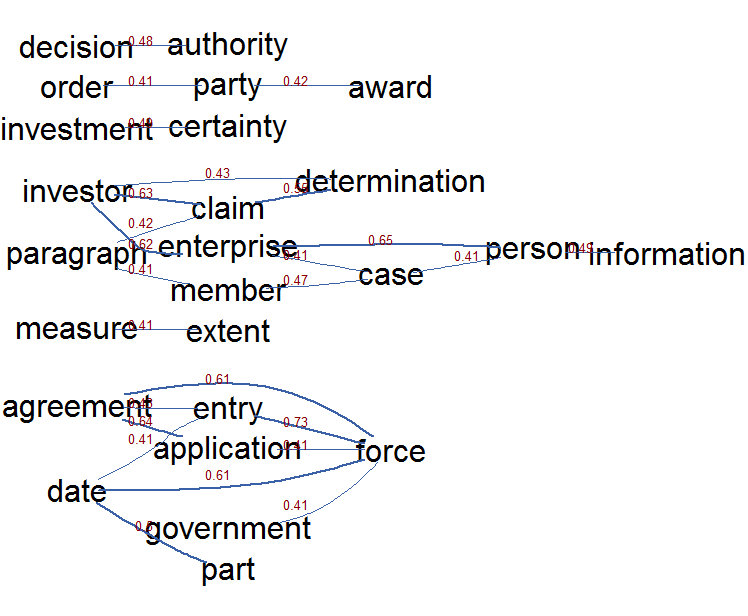
In text mining, you have a lot of terms, you can reduce the many word links to relevant links with the EBICglasso function from the qgraph package. This function allows to reduce the correlation matrix between the words to a similar matrix where correlations which are not relevant are set as much as possible to zero so that these do not need to be visualised. The following R code does this and visualises the positive (green) and negative (red) correlations which are left in the correlation matrix of words emmited by all topics. There is clearly and accreditation body which assess conformity according to regulations, an arbitration panel, and a lot is linked to each other regarding access to the market and the government which ensures the legality of the agreement.
library(Matrix)
library(qgraph)
terms <- predict(ceta_topics, type = "terms", min_posterior = 0.025)
terms <- unique(unlist(sapply(terms, names)))
out <- dtm[, terms]
out <- cor(as.matrix(out))
out <- nearPD(x=out, corr = TRUE)$mat
out <- as.matrix(out)
m <- EBICglasso(out, n = 1000)
qgraph(m, layout="spring", labels = colnames(out), label.scale=FALSE,
label.cex=1, node.width=.5)

4. If you think of it, words are basically also a network which can be visualised
R packages semnet and visNetwork are your friends here. Words which occur next to each other or within a certain window can be extracted and visualised. Package semnet uses the igraph package for this, package visNetwork allows to generate HTML output to be published on websites. Example graphs are shown below.
library(semnet)
terms <- unique(unlist(sapply(ceta_topic_terms, names)))
cooc <- coOccurenceNetwork(dtm[, terms])
cooc <- simplify(cooc)
plot(cooc, vertex.size=V(cooc)$freq / 20, edge.arrow.size=0.5)
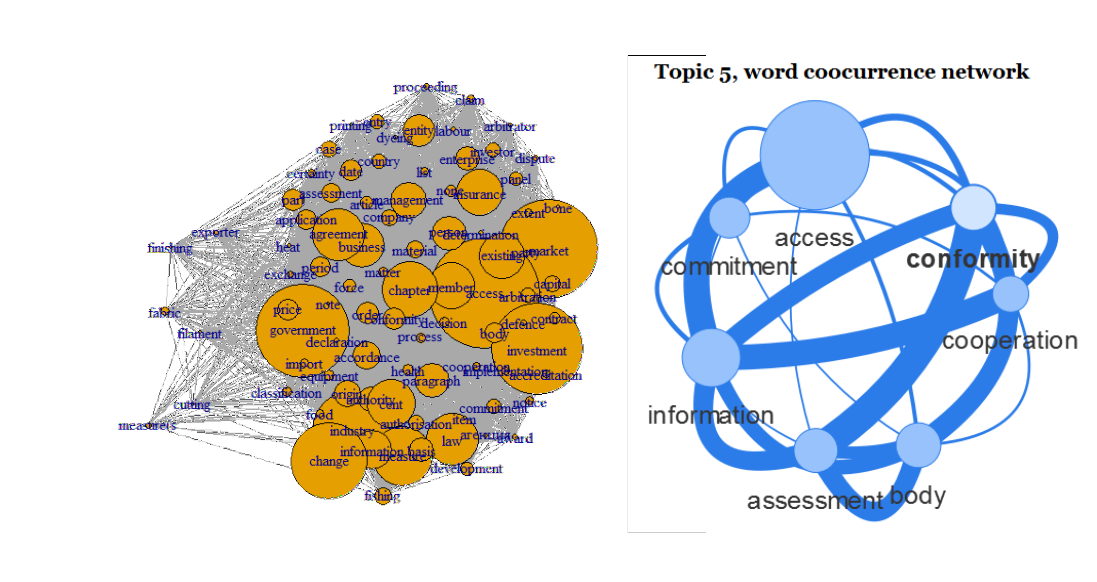
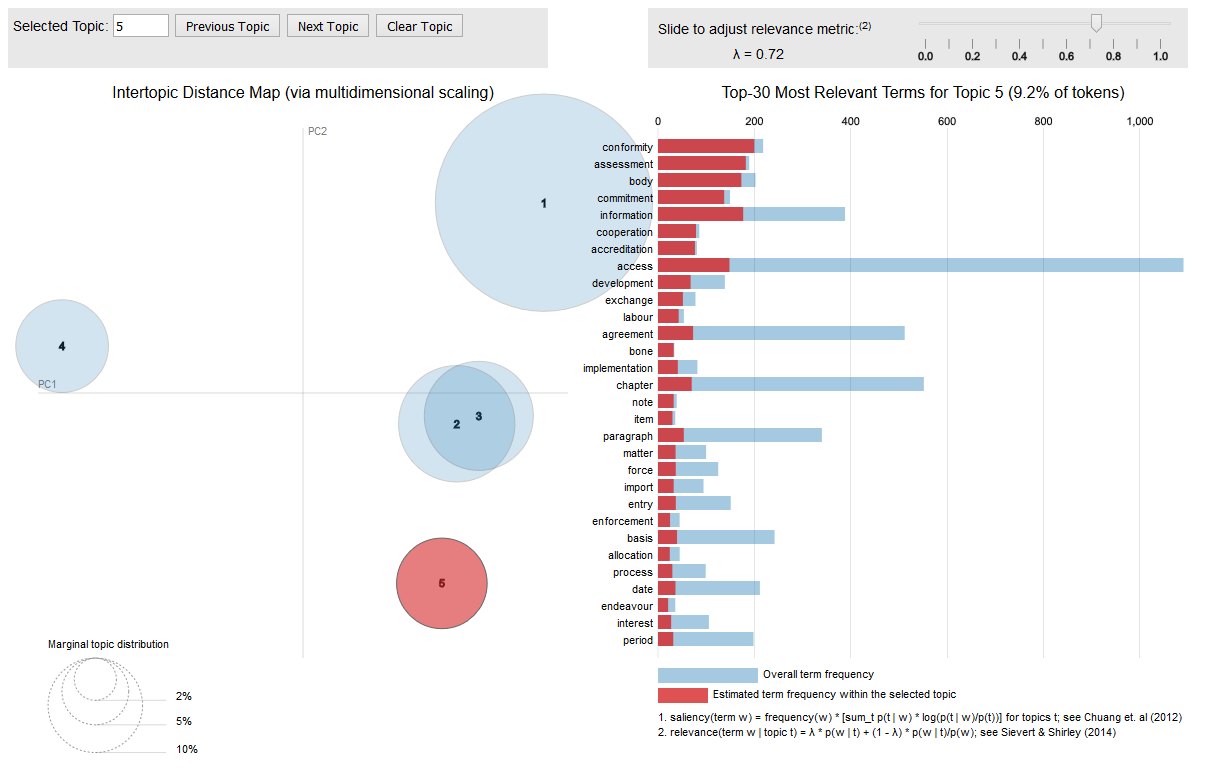
5. And of course you can find topics and visualise these topics
If you are interested in topic models, like the one fitted on the CETA treaty, you should have a look at the excellent LDAvis package which allows you to interactively explore the most salient words that each topic emits and as well visualises the distance between the topics.
The visualisation is interactive and can be put into a web application easily. The following call to the createJSON and serVis R functions from the LDAvis package give you an interactive topic visualisation in no time.
library(LDAvis)
json <- createJSON(phi = posterior(ceta_topics)$terms,
theta = posterior(ceta_topics)$topics,
doc.length = row_sums(dtm),
vocab = colnames(dtm),
term.frequency = col_sums(dtm))
serVis(json)
Hope this triggers you a bit to do text mining with R.
If you are interested in all of this, you might be interested also in attending our course on Text mining with R.
Our next course on Text Mining with R is scheduled on 2016 November 14/15 in Brussels (Belgium): more info + register at http://di-academy.com/event/text-mining-with-r/
Our next course on Text Mining with R is scheduled on 2017 March 23/24 in Leuven (Belgium): more info + register at https://lstat.kuleuven.be/training/coursedescriptions/text-mining-with-r