Sentiment analysis and Parts of Speech tagging in Dutch/French/English/German/Spanish/Italian
As part of our continuing effort to digitise poetry and to automate new forms of poetry, we released an R package called pattern.nlp, which is available at https://github.com/bnosac/pattern.nlp . It allows R users to do sentiment analysis and Parts of Speech tagging for text written in Dutch, French, English, German, Spanish or Italian. Of course this can also be used for other purposes like data preparation as part of a topic modelling flow.
![]()
If you are interested in text mining, feel free to register for the text mining courses listed at our last blog post.
If you just want to do sentiment analysis and POS tagging in these 5 European languages, go ahead as follows. Sentiment analysis is available for Dutch, French & English.
library(pattern.nlp)
## Sentiment analysis
x <- pattern_sentiment("i really really hate iphones", language = "english")
y <- pattern_sentiment("de wereld is een mooie plaats, nietwaar sherlock", language = "dutch")
z <- pattern_sentiment("j'aime Paris, c'est super", language = "french")
rbind(x, y, z)
polarity subjectivity id
-0.80 0.90 i really really hate iphones
0.70 1.00 de wereld is een mooie plaats, nietwaar sherlock
0.65 0.75 j'aime Paris, c'est super
Parts of Speech tagging is available for Dutch, French, English, Spanish & Italian.
library(pattern.nlp)
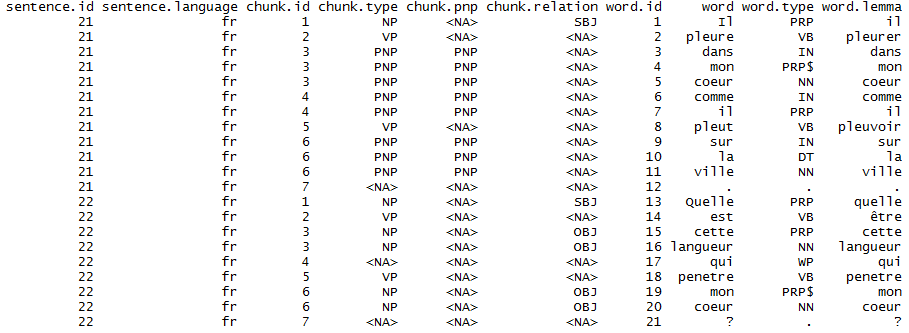
x <- "Il pleure dans mon coeur comme il pleut sur la ville. Quelle est cette langueur qui penetre mon coeur?"
pattern_pos(x = x, language = 'french')
x <- "Avevamo vegliato tutta la notte - i miei amici ed io sotto lampade
di moschea dalle cupole di ottone traforato, stellate come le nostre anime,
perché come queste irradiate dal chiuso fulgòre di un cuore elettrico."
pattern_pos(x = x, language = 'italian')
We are also working on a Dutch wordnet - which will be fully released in due date. More information at https://github.com/weRbelgium/wordnet.dutch.Hope you use the package for spreading new languages!