Massive online data stream mining with R
A few weeks ago, the stream package has been released on CRAN. It allows to do real time analytics on data streams. This can be very usefull if you are working with large datasets which are already hard to put in RAM completely, let alone to build some statistical model on it without getting into RAM problems.
Most of the standard statistical algorithms require access to all data points and make several iterations over the data and are less suited for usage in R on big datasets.
Streaming algorithms on the other hand are characterised by
- single passes over the data,
- using a limited amount of storage space and RAM
- work in a limited amount of time
- be ready to use the model at any time

The stream package is currently focussed on clustering algorithms available in MOA (http://moa.cms.waikato.ac.nz/details/stream-clustering/) and also eases interfacing with some clustering already available in R which are suited for data stream clustering. Classification algorithms based on MOA are on the todo list.
Current available clustering algorithms are BIRCH, CluStream, ClusTree, DBSCAN, DenStream, Hierarchical, Kmeans and Threshold Nearest Neighbor.
The stream package allows you to easily extend the use of the models with different data sources. These can be SQL sources, Hadoop, Storm, Hive, simple csv files, flat files or other connections. It is quite easy to extend it towards other connections. As an example, the following code available at this gist (https://gist.github.com/jwijffels/5239198) allows it to connect to an ffdf from the ff package. This allows to do clustering on ff objects.
Below, you can find a toy example showing streaming clustering in R based on data in an ffdf.
- Load the packages & the Data Stream Data for ffdf objects
require(devtools)
require(stream)
require(ff)
source_gist("5239198")
- Set up a data stream
myffdf <- as.ffdf(iris)
myffdf <- myffdf[c("Sepal.Length","Sepal.Width","Petal.Length","Petal.Width")]
mydatastream <- DSD_FFDFstream(x = myffdf, k = 100, loop=TRUE)
mydatastream
- Build the streaming clustering model
#### Get some points from the data stream get_points(mydatastream, n=5) mydatastream #### Cluster (first part) myclusteringmodel <- DSC_CluStream(k = 100) cluster(myclusteringmodel, mydatastream, 1000) myclusteringmodel plot(myclusteringmodel) #### Cluster (second part) kmeans <- DSC_Kmeans(3) recluster(kmeans, myclusteringmodel) plot(kmeans, mydatastream, n = 150, main = "Streaming model - with 3 clusters")
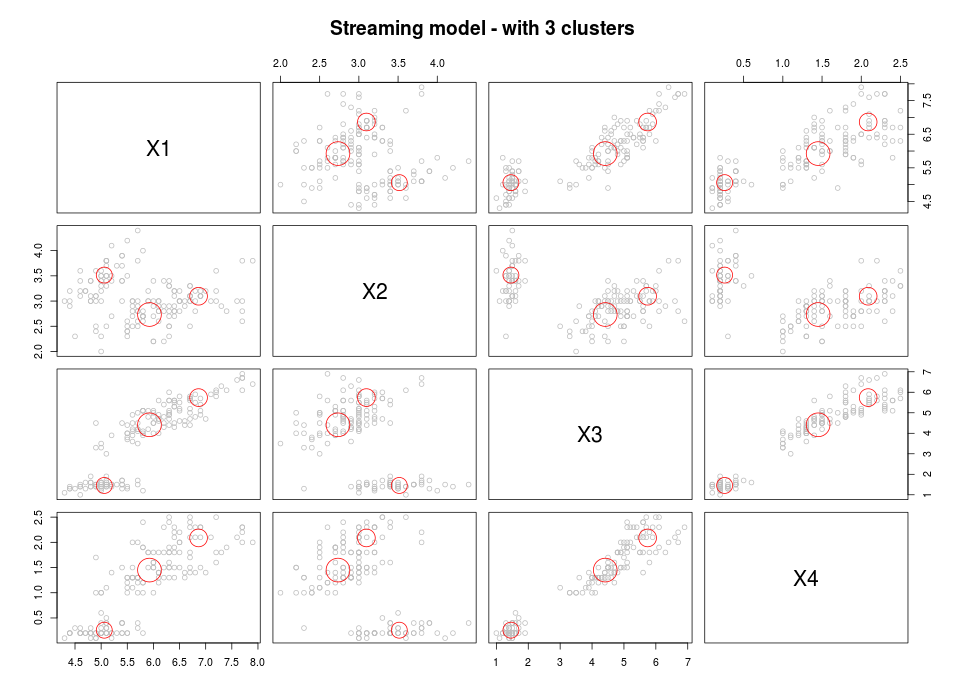
This approach is a standard 2-step approach which combines streaming micro clustering with macro clustering using a basic kmeans algorithm.
If you need help in understanding how your data can help you, if you need training and support on the efficient use of R, let us know how we can help you out.